How to Write Useful Commit Messages
Effective commit messages simplify the code review process and aid long-term code maintenance. Unfortunately, commit messages don’t get much respect, so the world is littered with useless messages like Fix bug or Update UI.
There’s no widespread agreement about what makes a good commit message or why it’s useful, so I’m sharing my thoughts based on my 20 years of experience as a software developer.
- An example of a useful commit message
- What’s the point of a commit message?
- Organizing information in a commit message
- What should the commit message include?
- A descriptive title
- A summary of how the change impacts clients and end-users
- The motivation for the change
- Breaking changes
- External references
- Justifications for new dependencies
- Cross-references to issues or other changes
- Summaries of bugs or external references
- Testing instructions
- Testing limitations
- What you learned
- Alternative solutions you considered
- Searchable artifacts
- Screenshots or videos
- Rants and stories
- Anything you’re tempted to explain outside of the commit message
- What should the commit description leave out?
- Further reading
An example of a useful commit message🔗
Here’s an example of a useful, effective commit message:
Delete comments for a post when the user deletes the post
In change abcd123, we enabled users to leave comments on a post, which we store in the post_comments table.
The problem was that when a user deletes their post, we don’t delete the associated comments from the post_comments table. The orphaned rows have no practical use, but they’re occupying space in our database and reducing performance.
This change ensures that we always atomically delete a post’s comments at the same time we delete the post itself by making the following changes to our database code:
- Updates the
DeletePostfunction to also delete comments in the same database transaction. - Adds a database migration to delete orphaned rows we added to
post_commentsprior to this change. - Adds a
FOREIGN KEYconstraint to thepost_commentstable so that we’ll hit a database error if we ever accidentally delete a post without deleting its associated comments.
Fixes #1234
This commit message is helpful for a few reasons:
- It presents the most important information early.
- It explains the motivation and effect of the change rather than just summarizing implementation details.
- It’s succinct and excludes useless noise.
- It cross-references related bugs and commit hashes.
What’s the point of a commit message?🔗
A commit message serves several roles, which I’ve listed below from most important to least important:
Helps your code reviewer approach the change🔗
When you send your code out for peer review, the commit message is the first thing your reviewer sees.
The code review is the most important scenario for a commit message, as effective communication at the review stage can prevent bugs or maintenance pitfalls before your code reaches production.
Communicates changes to teammates, downstream clients, and end-users🔗
Beyond your reviewer, other people on your team want to understand if your changes impact their work.
If you’re working on an open-source codebase or a project with downstream clients, your commit messages also inform your clients and end-users about how your change impacts them.
Facilitates future bug investigations🔗
After you merge your change, your code will live in the codebase for years or maybe even decades. Developers frequently review the commit history to diagnose bugs and to understand the software, so a clear commit message speeds their investigations.
Provides information to development tools🔗
Many development tools scrape information from commit messages to automate software development chores, such as cross-referencing bugs or generating release notes.
Organizing information in a commit message🔗
Put the most important information first🔗
In a long commit message, most readers don’t want to read the entire thing, so put the most important information at the beginning. This allows the reader to stop reading as soon as they reach the information that’s relevant to them.
Journalists call this writing style “the inverted pyramid.” A good news report begins with the details that readers care about most. As the article progresses, it narrows its focus to details that interest only the most engaged readers.

Journalists structure news reports in an inverted pyramid, where the information relevant to the most people is at the top.
Use headings to structure long commit messages🔗
Headings create structure in a long commit message, making it easier for the reader to find information relevant to them:
Respond with HTTP 400 if book title contains HTML tags
With this change, we completely reject requests where the book title contains any HTML tags.
Background
We have never allowed HTML in book titles, and our documentation says titles must contain only alphanumeric characters. Prior to this change, we tolerated clients embedding HTML in their book titles because we’d strip out the HTML server-side.
Motivation
In bug #1234, a user abused our sanitization so that sanitizing the title would actually create a <script> tag that the attacker used to inject malicious JavaScript. We fixed that in abcd123, but then a few months later, in #4321, an attacker found a way to inject code through the onload attribute.
There is no valid reason for a client to include HTML tags in the title, so if we’re seeing them, it’s either a misbehaving client or a malicious user.
Alternative 1 - CSP: Poor library compatibility
The other way we can handle this is with Content Security Policy (CSP), which would prevent inline JavaScript. The problem is that it would break too many of our existing libraries.
Alternative 2 - Output encoding: Error-prone
We could also rely on output encoding so that we always render the HTML as text characters as opposed to HTML. We’d have to get that right 100% of the time we display the title or strings that include the title, so it’s too risky.
What should the commit message include?🔗
For a simple change, a one-line commit message could be sufficient. The more complex the change, the more detail the commit message needs.
The following is a mostly-exhaustive list of details that could be useful in a commit message.
A descriptive title🔗
The first line is the most important part of the commit message because it’s what appears in the commit history of most git UIs.
When you print the commit summary using git log --oneline, it prints the first line of each commit message:
$ git log --oneline
fd8902a (HEAD) Combine tests in reviews_test (#421)
32dbf9a Log error information on account handler errors (#420)
dea3e7a Stop using npm scripts to check frontend (#418)
20ec3c6 Upgrade to sqlfluff 3.3.0 (#417)
4383920 Make prettier ignore .direnv directory (#416)
cacf31b Make Nix version of Go match Docker version (#414)
c6489bf Lint SQL in pre-commit hook (#415)
GitHub and other git UIs also show the first line of each commit message prominently in the change history:
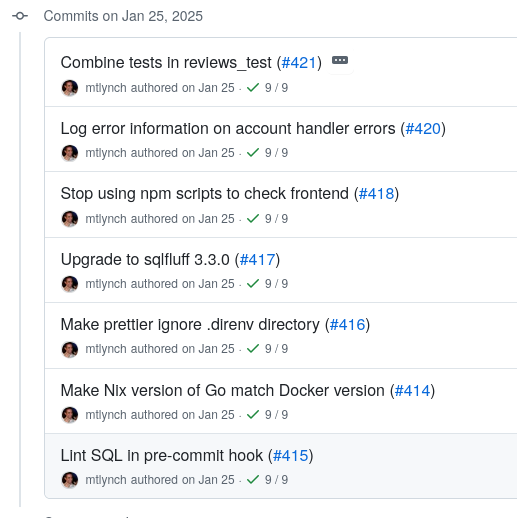
GitHub shows the first line of the change description in the change history
Your teammates and users can’t read every line of every change to the codebase, so the title is the primary way that you communicate whether the change is relevant to them.
The title should describe the effect of the change rather than how you implemented it. That is, the “what” rather than the “why” or “how.”
In a change where you add a mutex to prevent a concurrency bug, this would be a poor title:
Add a mutex to guard the database handle
A better title explains the effect of the change. What’s different about the application now that there’s a mutex?
Prevent database corruption during simultaneous sign-ups
A summary of how the change impacts clients and end-users🔗
Usually, you can’t capture all of the relevant details about a change in the title alone, so the subsequent lines of the commit message should fill the gaps.
Keep in mind that, for some audiences, their goal is to understand how the change impacts them without having to read the code itself. It could be because they’re an end-user who can’t understand software code, or they might just be a busy developer who doesn’t have time to read every diff.
Ensure that the commit message explains the relevant details of the change even for someone who won’t read the diff itself.
The motivation for the change🔗
After you communicate what the change does, the most important thing to communicate is “why?”
Why are you making this change? How does your change align with the team’s goals? What considerations led you to this particular solution?
Consider this example:
Change background from blue to pink
This updates the CSS so that the application’s default background is pink, when previously it was blue.
If a year from now, your teammate wonders why the background is pink, they’d read the above commit message and get zero useful information.
Instead, explain the motivation for the change in the commit message:
Change background from blue to pink
Our current blue background makes links difficult to see:
This changes our background to pink because I think that matches our app’s personality, and it makes the links more legible:
The above explanation makes the motivation and reasoning clear. If another developer wants to change the background in the future, they’ll understand the constraints that guided the decision to make the background pink.
Sometimes, a change’s motivation depends on future plans. You may have a grand vision for how a change is just step one of a beautiful new architecture, but your teammate can’t read your mind to see it.
When you send a commit out for review, use the commit message to communicate how the change fits into any larger designs you have in mind.
Breaking changes🔗
If downstream clients will have to rewrite code or change their workflows as a result of the change, the commit message should explain what’s changing and how clients should handle it.
Use recognizable conventions to make it easy for clients to identify breaking changes. Ensure that your process for creating release announcements scans the commit history to surface details about breaking changes.
Require a signed hash on all requests
To prevent malicious clients from abusing the server, we’re now requiring signed hashes on all requests so that the server can authenticate them as valid.
Breaking change
Clients using v2 libraries will no longer be able to access the server. They will need to switch to a v3 or later client implementation.
External references🔗
Link to any external documentation or blog posts that influenced your design or implementation choices.
You shouldn’t dump your entire browsing history into the commit message (for many reasons), but you should link to the non-obvious resources that will help your teammates understand your thinking.
This change calls the database/sql library, which is documented on the Go docs site:
I chose the zombiezen/go-sqlite SQLite driver, as it outperforms other implementations in high-concurrency scenarios:

Justifications for new dependencies🔗
If a change adds a new third-party dependency, flag it in the commit message, and explain why you’re adding it.
Dependencies are a long-term maintenance burden and a frequent source of bugs. It’s helpful for your teammates to understand why you’re adding the dependency and how you selected it.
Note: If you’re a JavaScript developer, ignore this note, and continue adding 12 new npm package dependencies in each of your commits.
Cross-references to issues or other changes🔗
On most git hosting platforms like GitHub, GitLab, and Codeberg, mentioning an issue by ID like #1234 automatically creates a cross-reference between the commit and the issue. Similarly, mentioning another change by pull request ID or commit hash creates a cross-reference.
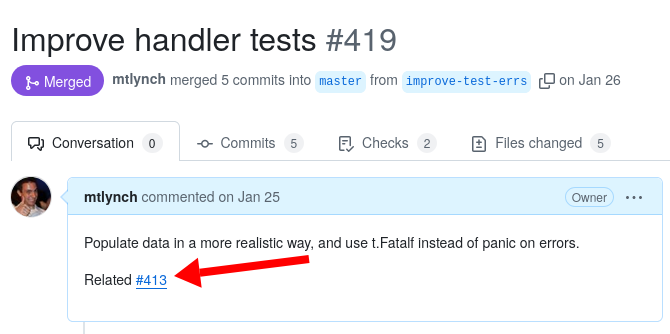
On most git hosting platforms, mentioning an issue by ID automatically creates a cross-reference between the commit and the issue.
There are also auto-closing keywords like Fixes or Resolves. When a commit message includes text like Fixes #1234, GitHub, GitLab, and Codeberg all know to auto-close issue #1234 when you merge the change.
Creating cross-references to related issues and other changes helps teammates and future maintainers understand the context around the change.
Summaries of bugs or external references🔗
When you link to a bug or an external reference, don’t just write Fixes #1234 and expect readers to read the entire ticket discussion, especially when the bug has a long, complex history. Summarize the relevant details for the reader.
Show error instead of blank screen after login
Fixes #1234
Warn user if they have a malicious Firefox extension
This change adds a check for the BreakRandomWebsites Firefox extension and warns the user on page load when we detect it.
Background
In #1234, a user reported that they got a blank screen after logging in on Firefox, but it worked fine on Safari.
It turned out that the user had the BreakRandomWebsites Firefox extension installed, which breaks our app, so we need a way to surface this information to the user more obviously.
Fixes #1234
Testing instructions🔗
Ideally, automated tests should exercise your changes, but if those don’t exist, explain to your reviewer how to test your code.
To test the new behavior:
- Populate the testing database with 400 users:
./scripts/populate-store --count 400 - Run the server in dev mode:
PORT=9000 TESTING=1 ./server - Open the login page in the browser:
http://localhost:9000/login - Log in as user
admin/admin - Under “Metrics” click “Delete All”
- Reload to see the server automatically repopulate the metrics tables
Testing limitations🔗
The default expectation is that you tested your commit to your team’s normal standards before sending it for review or merging it in the codebase.
In some cases, it’s impractical to test a change in all the relevant scenarios. If that happens, disclose what scenarios you haven’t tested. It will help your reviewer assess the risk of the change, and it will provide an answer when future maintainers ask, “Did this code ever work correctly?”
I don’t have a bare-metal RISC-V machine to test this on, but I emulated RISC-V on my AMD64 dev system using qemu, and it worked as expected.
./dev-scripts/run-tests --qemu-emulate riscv64
What you learned🔗
Use the commit message to capture what you learned while implementing the change.
You’ll be glad you wrote it down while it’s fresh in your mind, and your teammates will be thankful that you spared them all from tracking down the same information.
You don’t have to be an expert on whatever you’re explaining — admit freely what you don’t understand. You’ll be surprised at how often your explanations help teammates you assumed knew everything.
Fix a bash bug in the benchmarking script
This fixes a bug in the benchmarking script related to pipe characters. See the pipelines section of the bash manual for more details:
https://www.gnu.org/software/bash/manual/html_node/Pipelines.html
Measure execution time more accurately in the benchmarking script
This fixes a bug in our benchmarking script that caused us to underestimate evm’s performance on our benchmarks.
evm has an internal performance timer that starts as soon as the program begins, but our benchmarking script had a bug that started evm’s timer before it could begin working, which made our benchmarks higher (worse) than they were in reality.
How bash pipelines actually work
I had a mistaken mental model that bash pipelines execute each process serially.
For example, consider this pipeline:
./jobA | ./jobB
I thought that in the pipeline above, jobA would run to completion, then the script would start jobB with jobA’s standard output as its standard input.
It turns out that what bash actually does is start both jobA and jobB simultaneously. jobB just blocks on input until jobA writes to standard output.
In retrospect, this makes total sense because I’ve seen plenty of pipelines where the second process begins processing output before the first process terminates, but I always modeled the pipeline incorrectly in my head.
One neat side effect of documenting your lesson is that the act of explaining it deepends your understanding. Sometimes, explaining your solution makes you realize there’s a better alternative you didn’t explore or a corner case you forgot to cover.
Alternative solutions you considered🔗
Often, you begin a change with a naïve solution and find some reason that it doesn’t work. When that happens, help your reviewer and future readers understand why the obvious solution didn’t work.
Ideally, the explanation should live in a comment within the code itself rather than in the commit message. Otherwise, everyone who reads the code will wonder why it’s doing the non-obvious thing.
I tried deleting the time.sleep() call, but that caused a deadlock between the renderer and the scheduler.
If it’s a decision that doesn’t have a logical place in the code, explain it in the commit message.
I originally tried to use std.xml.Parser, but it doesn’t include line-level metadata, which we need for printing error messages.
Searchable artifacts🔗
If a change is related to a unique error message, make sure that the text of the error appears in either the commit message or in a bug that the commit cross-references.
Including the error message ensures that if you encounter that error in the future, you can use git log --grep or the search function of your git hosting tool to find past work related to the error.
$ git log --pretty=format:"%s%n%n%b" --grep "reading 'parentNode'"
Fix unclosed div in index.html
On about 30% of builds, the build was failing with this error message:
Cannot read properties of null (reading 'parentNode')
It turned out to be caused by an unclosed div in one of our files.
Beyond error messages, think about other terms that you or a teammate might search to find related commits, such as names of components, projects, or client implementations.
Screenshots or videos🔗
For changes to an app’s user interface, videos and screenshots can be helpful, especially if you show the before and after.
Don’t spend hours trying to produce a perfect, Oscar-winning screencast — a simple 15-second demo can make a major difference for your teammates trying to understand the change.
A video should supplement the commit message, not replace it. A rambly, five-minute screencast is a poor substitute for a succinct and well-organized commit message.
The drawback of embedded media is that git doesn’t support it natively. If you use git through a platform like GitHub or GitLab, it’s easy to embed images in pull request descriptions, which you can subsequently convert to be the commit message for the change.
If you don’t use a UI for git that supports embedded media, you can still upload your media to permanent storage and link it as a plain URL in your commit message, though that increases the risk of links going dead if the storage location goes offline or moves. In these cases, it makes more sense to share the screenshots or video in a review comment rather than in the commit message.
Rants and stories🔗
Stories and passionate rants about the code are fun and sometimes informative, so feel free to include them, but save them until the end.
If someone’s chasing a high-priority bug at 2 AM, they don’t want to read 20 paragraphs about your adventure writing this change or your snarky critiques of a bad library.
Tame the wicked beast that is the load balancer
Gather friends, as I tell you a tale about my glorious fight with the dastardly foe that we know and love: the load balancer.
It all started back in 1983, when I was a freshman at Diltmore College…
[50 paragraphs later]
When I woke up, my tonsils were missing, and cuddled next to me in bed were 15 stray puppies that I had no memory of adopting.
A sensation in my hand caused me to look down. I was holding a piece of paper smeared with what was unmistakably McDonald’s barbecue sauce. Looking closer, I realized the sauce spelled out a single word: goggle.
I snapped open my laptop and ran grep -i goggle ./src. Everything suddenly made sense.
There was a typo in our config file that was causing us to ping goggle.com rather than google.com, so this change fixes the typo.
Present critical details succinctly at the top of the commit message, and append the rant to make it obviously extra credit reading.
Fix google.com typo in the load balancer’s connectivity check
Due to a typo introduced in abc1234, the load balancer was checking for a live HTTP server at goggle.com rather than the intended google.com.
This fixes the typo so that we send HTTP requests to google.com to verify that the load balancer has Internet connectivity.
Rant (just for fun)
Gather friends, as I tell you a tale about my glorious fight with the dastardly foe that we know and love: the load balancer…
Anything you’re tempted to explain outside of the commit message🔗
Sometimes, when someone sends me code to review, they write me an accompanying email to explain background information. If I’m particularly unlucky, they’ll interrupt me at my desk to give me a brief lecture that I’m supposed to remember while reviewing their code.
In these cases, I gently tell my teammate that we actually already have a great place to share this information with me: the commit message!
Resist the temptation to explain details about your change outside of the commit message or the code itself. If you need to set the stage before a review for your reviewer, do it in the commit message. That way, your reviewer will see it, and so will anyone else who ever needs that information as well.
What should the commit description leave out?🔗
It’s better to err on the side of overcommunicating in a commit message, but there’s also value in reducing noise. Look for opportunities to cut unnecessary information wherever possible.
Information that’s obvious from the code🔗
Avoid mentioning facts in the commit message that the code makes plainly obvious. Examples include:
- A list of files you edited
- What APIs you called
- Whether it’s a large or a small change
The reader will trivially learn those details when they look at the code, so you don’t have to spell it out for them.
Critical details about maintaining the code🔗
You should capture crucial details about maintaining the code, but they’re too important to bury in the commit message. Future maintainers might not think to check there when making changes.
If your teammates need to know something about the code, put the information in the code itself, ideally with automated checks to prevent anyone from violating the code’s assumptons.
In disk.c the offset is 32, but in file.c, the offset is 16.
The 2:1 ratio is critical, so, if we ever change one of these values in the future, we have to maintain the ratio. Otherwise, the server will silently corrupt all user data, including our offsite backups.
I haven’t documented this in the code, as I assume all future maintainers will always follow the blame history to this commit message before editing either of the two files.
Short-term discussion🔗
Consider whether the details you’re adding to the commit message are useful to keep in the source history forever or if they’re just ephemeral discussion that’s useful right now.
If the information is only relevant during the code review, add it as a comment in the discussion for the pull request or bug rather than including it in the commit message forever.
@mtlynch - Can you look at this and tell me if I’ve gone bonkers?
Preview URLs and build artifacts🔗
If your continuous integration system produces preview URLs or build artifacts that are useful to your reviewers, they should be easy for the reviewer to access, but it shouldn’t be the author’s job to add them to the commit message manually. Invest in tooling that automatically surfaces the information during the code review.
The more toil you add to the commit message, the more people will perceive it as a mechanical chore rather than an opportunity to communicate useful information.
Consider the lifetime of the build artifacts. If they’ll only remain available for a few weeks, then links to build artifacts become distracting noise in the commit message. They should live in the discussion channel rather than the commit message itself.
Further reading🔗
- “Writing commit messages,” by Simon Tatham, author of the PuTTY SSH client
